Latest organic search news – April 26
We’ve compiled the essential updates from Google and the broader world of search from the last month – keeping you up to date with everything you need to know.
TL;DR
- GEO is not just about understanding visibility. Peec’s webinar highlights sentiment, source-level insight and how LLMs actually describe brands, not just whether they appear.
- Search is becoming even more personalised. Google’s “Personal Intelligence” connects user data across products, meaning the same query can return different answers depending on the individual – US rollout.
- AI visibility decays quickly. Citations have a ~4–5 week half-life, reinforcing the need for consistent, always-on digital PR activity.
- Search is moving towards an “agentic” model. Google-Agent signals a shift from ranking pages to enabling systems to interact with websites directly.
- Content needs to be clearer, not just structured. LLMs read language, not just schema. If your content isn’t explicit, it’s harder to interpret and reuse.
- Core and Discover updates land back-to-back. Probable cause of any recently experienced volatility.
Peec webinar: how the professionals use the tool
Peec hosted a great webinar this month on how to leverage the tool to maximise GEO success,, how the platform is intended to be used day-to-day, and how to frame it with clients and prospects.
I highly recommend anyone interested in improving their LLM visibility to watch this, in-house or agency-side.
A couple of points stood out.
Sentiment on branded prompts
When tracking branded queries, sentiment scoring becomes more useful than it first appears.
By clicking into individual LLM responses, you can see:
- whether your brand is being described positively or negatively
- which sources are influencing that response
That immediately adds more context to visibility data. It is not just whether you are present, but how you are being represented.
Working backwards from the response
One of the more useful ways to think about this is that the LLM has already done the heavy lifting.
It has crawled multiple sources, interpreted them, and synthesised what it considers the most relevant answer. That output is effectively the model’s current perception of your brand for that query.
From there, you can work backwards:
- analyse the response itself
- identify the sources being used
- understand why that narrative exists
If the sources cited are ones you control, it is often a relatively quick fix. If not, it gives a clear view of what is shaping perception and where content or PR activity should be focused.
One example from our side: a two-year-old LinkedIn post appeared as a primary source of information for a branded prompt. Not something that would typically surface through standard SEO analysis, but clearly influencing how the brand is being described. How much has your business changed in two years?
Once you have a month’s worth of chat responses to a prompt, you can analyse them en masse and start to compile all the things people do not love about your offering. And from that, start to put plans in place to counter them, from content marketing and PR all the way through to the product teams.
This process is much quicker than other approaches to this concept and is particularly important when trying to control a narrative around a particular product or service, as we know, once LLMs start to build a picture of something, it can become gospel (rightly or wrongly) very quickly if sources are left unchecked.
Using this beyond negative prompts
The same approach applies to positive prompts.
When LLMs describe your brand favourably, those responses highlight what the model associates you with and where you are strongest. These can be treated as “marketing trophies” and reinforced across key touchpoints and channels.
This can also be extended to competitors. Analysing how LLMs describe rival brands, both positively and negatively, provides useful market context and can surface positioning gaps, messaging opportunities and areas of differentiation.
Where this is heading
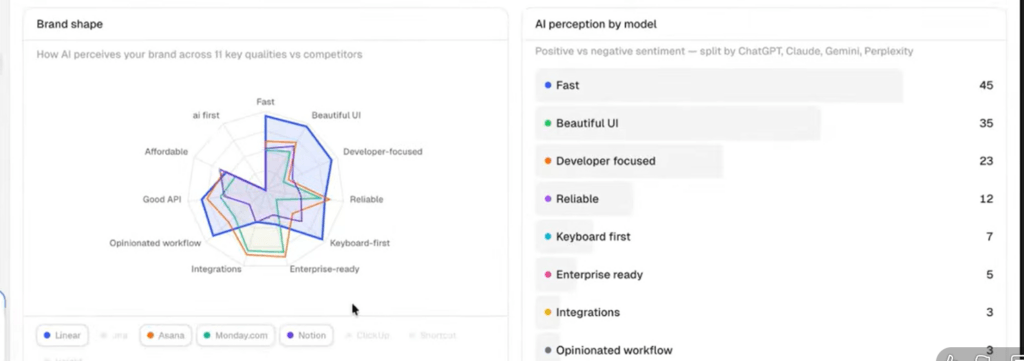
Peec also previewed a “brand perception” feature, designed to show how LLMs position a brand across various features and offerings. For example, brand A is stronger across XYZ but brand B has a more favourable LLM perception across 123.
This aligns closely with some of the manual analysis we have been doing. It shifts the focus from simple visibility tracking to understanding how a brand is actually interpreted, which is ultimately the more useful question.
Given the pace of change in the space, our ethos remains the same: continue testing tools, models and methodologies to understand what is actually influencing visibility across the touchpoints our clients care about most. Peec.ai is a useful addition here, particularly for turning LLM outputs into something more actionable.
Google expands Personal Intelligence across search and browsing
Google expanded its “Personal Intelligence” feature in March, rolling it out across AI Mode in Search, the Gemini app and Gemini in Chrome in the U.S.
At a product level, this is about connecting Gemini more deeply with a user’s Google ecosystem. By linking services such as Gmail, Photos, YouTube and Search, responses can now be shaped using a combination of real-time web data and personal context.
The practical shift is that answers are no longer based solely on the query itself. They are influenced by what Google already knows about the user, their history, preferences and behaviour.
Search has always had elements of personalisation, but this takes it a step further. The same query may/will now produce materially different responses depending on the individual, particularly within AI Mode.
For brands, this reinforces a broader trend we are already seeing. Visibility is no longer just about ranking for a keyword. It is about being present across the wider set of sources and touchpoints that inform these responses.
For digital marketers, our task is to continue to build as clear a picture as possible of customer profiles and ensure coverage across the platforms and content types that shape those journeys.
We covered this in more detail in our recent webinar on how data can power digital PR and AI visibility.
The half-life of AI citations – and what this means for digital PR consistency
A recent study by Scrunch, analysing 3.5 million AI citation events, found that the average half-life of an AI citation is roughly 4-5 weeks.
In simple terms, within a month, roughly half of the sources referenced in AI answers are replaced.
There is some variation by platform:
- ChatGPT: ~3.4 weeks
- Perplexity: ~5.8 weeks
- Google AI products: ~4.3–4.8 weeks
But the overall pattern is consistent. AI visibility is not stable. Citations appear, decay and need to be reinforced.
One of the more interesting findings was the role of editorial distribution. Content published across larger, trusted networks tended to persist for longer, in some cases almost twice as long.
That aligns with what we’re already seeing. Trusted editorial sources continue to play a significant role in how LLMs build responses.
The implication is fairly clear. Occasional campaigns may drive short-term visibility, but maintaining presence requires more consistent activity.
For brands, this means:
- Regular research releases and data studies
- Ongoing expert commentary and reactive PR
- Consistent pitching to high-authority publications
Success in AI search isn’t just about ranking a page once and maintaining it. It’s about continually feeding the ecosystem with credible signals through both content and earned media – and that’s where the competitive advantage lies.
Google-Agent and the shift towards an “agentic web”
Marie Haynes published an great blog this month on Google’s introduction of a new “Google-Agent” user agent and what it signals for the direction of search.
Her view is that this represents a broader shift towards what she describes as an “agentic web”, where AI systems move beyond retrieving information and begin interacting with websites directly.
Rather than users clicking through results in the traditional sense, agents could complete tasks on their behalf. That might include extracting structured data, filling out forms or even completing transactions, depending on how sites are set up.
This is being enabled by emerging protocols and infrastructure changes, such as Model Context Protocol (MCP) and WebMCP, which are designed to allow systems to interact with site functionality rather than just rendering content.
It is a significant shift in how the web could operate, but it is still early. Most sites will not see a direct impact from this in the short term, and there are still a number of unknowns around how quickly this develops.
What is useful, though, is the direction it points to.
Search continues to move away from a model based purely on ranking pages and driving clicks, and towards one where systems interpret, extract and act on information.
From Marie’s perspective, this is not something to be wary of, but something to lean into. If agents can interact directly with websites, the opportunity moves beyond visibility into action.
From an SEO standpoint, that reinforces a few themes we are already seeing:
- content needs to be clear, structured and machine-readable
- entities and relationships matter more than pages alone
- visibility is not just about being clicked, but being used
It also builds on the earlier point around AI Overviews and Gemini. If more of the journey is handled within the interface or by agents, then the role of a website shifts from being a destination to being a data source.
The upside here is that SEO is no longer limited to traffic. If this direction plays out, it has the potential to influence outcomes more directly, whether that is leads, transactions or other forms of engagement.
From structured data to structured language
Following on from Marie Haynes’ point above around an “agentic web”, a fascinating article this month from Ramon Eijkemans looked at how content itself may need to evolve in response.
The argument is that while structured data still has a role to play, it is no longer enough on its own. LLMs are not querying markup in the same way traditional search engines did. They are interpreting natural language and extracting meaning from it.
That shifts the emphasis from how data is tagged to how it is written.
If agents are interacting directly with content, rather than just indexing it, then more of that structure needs to be embedded within the language itself. Entities, relationships and key attributes should be clearly stated, not implied.
In practical terms, that means:
- being explicit about what something is, who it is for and how it relates to other things
- avoiding vague or indirect phrasing
- structuring sentences so they can be easily extracted and reused
This ties closely to a number of the other themes covered this month. Front-loaded content, clear answers and strong entity definition all make it easier for models to interpret and use your content.
The article itself is worth twenty minutes of your time. One practical way I have been approaching this is by using it to guide AI-assisted rewrites of existing pages, testing whether more explicit, structured language changes how content is interpreted and surfaced.
The real skill, though, is balancing this with the human experience. Writing in a way that is clear for agents while still being logical and compelling for users. As with most things at the moment, it is possible to go too far towards AI optimisation at the expense of your actual audience. If users do not engage with your content, Google will pick up on that and visibility will likely suffer.
It is not a replacement for structured data, but a shift in emphasis. Schema is still critical, but clarity in the content itself is increasingly what determines how well it can be interpreted and reused.
March 2026 core update (and Discover update follow-up)
Google began rolling out a broad core update in early March, just a few weeks after February’s Discover-specific core update.
Nothing particularly unusual in terms of direction. As with most core updates, this appears to be a standard re-evaluation of content quality, relevance and trust signals rather than anything targeting a specific tactic.
The more notable point is the sequencing. A Discover-focused update followed quickly by a broader core update suggests Google is continuing to refine how content is surfaced across different parts of its ecosystem, not just traditional search.
If you’ve seen volatility over the past few weeks, this shuffling of the pack is a probable cause.
Enjoyed this roundup? Stay updated with the latest Organic trends, tips, and exclusive insights by subscribing to our newsletter.
Want cutting-edge digital news and tips straight to your inbox? Sign up to our monthly newsletter here
"*" indicates required fields